TAKE NOTE (Insights and Emerging Technology)

U.S. Army Program Executive Office for Enterprise Information Systems, recently launched the Army Contract Writing System, a platform designed to provide the Office of the Deputy Assistant Secretary of the Army for Procurement with a single enterprise writing and management system to streamline the Army contracting process.
The initial user group includes 104 contracting personnel at 29 locations including Army Contracting Command-Joint Base Lewis-McChord and offices across the Army National Guard who will provide feedback on the system prior to the next release.
“We’re proud to provide significantly improved integrated contract writing capabilities for the contracting workforce, enabling them to work faster and more efficiently to help the Army meet its mission,” said Megan Dake, DASA for Procurement. “We owe our teammates this, and we’ll continue to get feedback and work with the product manager to improve the system as more capability is rolled out to larger organization.”
During this initial deployment, the ACWS will enable users to:
- Generate solicitation, award and modification documents in Uniform Contract Format
- Generate Procurement Data Standard-compliant transactions
- Import vendors from the System for Award Management
- Link to the Procurement Integrated Enterprise Environment Clause Logic Service to complete required clause interviews
- Receive purchase requests from the Defense Enterprise Accounting and Management System
- Connect to the Federal Procurement Data System to complete contract action reports
The next rollout of ACWS, which will include approximately 350 additional users from Army Contracting Command and the Army National Guard, is planned for the first quarter of fiscal year 2024. ACWS will eventually replace the Standard Procurement System/Procurement Desktop-Defense and the Procurement Automated Data and Document System.
Interested in learning more about RPA? Download our FREE White Paper on “Embracing the Future of Work”

UNDER DEVELOPMENT (Insights for Developers)
Data Mesh Explained
Intro
Organizations worldwide handle large data volumes to complete various transactions. The challenge, however, comes when analyzing enormous data, especially if you have multiple sources. In addition, if you have many business streams, it may be tedious to control how to access and share data with different users.
A data mesh comes in handy to address the complexities of data security and control. It helps you manage, share, and control all your data streams from a central domain, regardless of the size.
Discover the key functionalities of a data mesh as part of your Data Architecture solution and how it works. For a quick recap of what a Data Architecture and Data Fabrics, see our blog Data Architecture – Understanding The Benefits and Data Fabrics Explained
What is a Data Mesh?
Data mesh is a decentralized framework that organizes and distributes data using a specific business domain. It can combine various data links into a unique domain from where you can manage, use, or share them on a distributed framework.
Here’s an example; assuming your organization consists of many departments, say marketing, sales, finance, and customer service. You receive multiple requests from external stakeholders daily to deliver products, services, or business information. Instead of handling client requests in batches, you can organize them in sub-domains and assign domain ownership to designated staff.
As a result, each department will serve its clients’ requests from a unique domain. Moreover, the department will determine, control, and access their domain since they better understand their products and client needs. (see below)
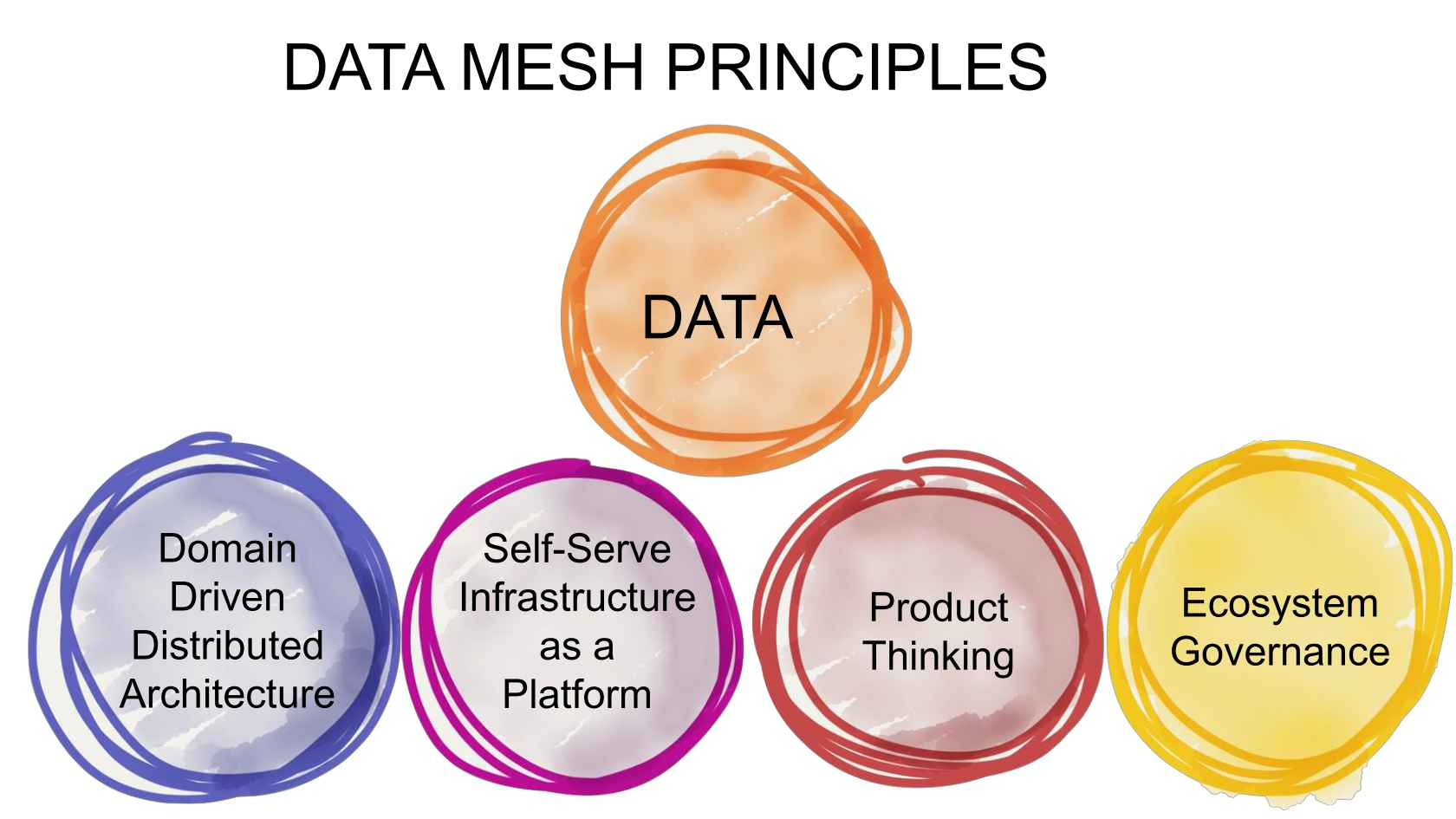
Core Principles of a Data Mesh
Zhamak Dehghani, a ThoughtWorks consultant, invented the data mesh concept in 2019. He emphasized that an organization that seeks to organize and deliver a reliable data enterprise should capitalize on the concepts for a successful implementation.
Dehghani’s core principles are as follows:
Data as a Product
A successful data mesh implementation requires each domain team to organize its data assets into unique products. Each data product should be clean, complete, and available to all users anytime, depending on the regulations. Moreover, to achieve the best user experience, data products should be;
Identifiable – the data product is registered under a central database for easy identification.
Addressed – the data has a unique address to help users access it.
Trustworthy – the product defines clear objectives and reflects the actual state of events.
Self-explanatory – the data product labels semantics based on the organization’s naming codes.
Domain-oriented Ownership
The data mesh concept requires organizations to build frameworks around business domains to reduce over-dependence on the primary data teams. For this reason, you should have different domain teams that collect, transform and distribute data based on their business functions.
For example, if you’re into fashion design, you can have a domain containing fashion products and a separate website for your visitors’ behavior analytics. That way, the fashion and data analytics teams will handle their data sets separately instead of piling all data into a central domain.
Self-serve Infrastructure
A self-serve infrastructure enables instant access to data by all users. It also reduces duplication of efforts since each domain will have a clean, filtered set of data products each time. For efficient management of the self-serve structure, the data engineers can handle the technology while the domain teams upload the relevant data products.
Federated Governance
A good data infrastructure allows shared responsibility for better control and implementation. Although it is okay for a domain team to handle its data products, federal data governance should also be available to monitor compliance with standards and policy implementations.
– Dig Deeper –
The differences between Data Fabric, Data Mesh, Data-centric revolution, FAIR data

Q&A (Post your questions and get the answers you need)

Q. I am reading about CI/CD Pipelines and DevOPS. Is this possible with SAP?
A. Well yes… at least now it is in S/4Hana.
SAP S/4HANA supports a range of DevOps tools that can be used to streamline the development, testing, deployment, and maintenance of SAP applications. While we can seamlessly use third-party tools like Git, Jenkins, Docker, and the like in SAP S/4HANA, there are also some great tools offered by SAP itself. Let’s take a look at two of these abapGit and Git-Enabled Change and Transport System. I’ll also make a book recommendation.
abapGit
abapGit is an open-source tool used for version control of ABAP development objects in SAP systems. It allows developers to manage ABAP source code in a Git repository, which provides a way to track changes, collaborate with other developers, and manage the development process more efficiently.
abapGit is a client-based tool that’s installed in the SAP system as an ABAP package. It integrates with SAP development tools such as the ABAP editor, the ABAP development workbench, and Change and Transport System (CTS) to enable developers to manage their ABAP source code in Git repositories.
With abapGit, developers can create, push, pull, and merge Git branches, manage Git repositories, and view Git history directly within the SAP system. This allows developers to manage their ABAP source code in the same way they manage other software projects, and it provides a familiar development environment for developers who are already familiar with Git.
Git-Enabled Change and Transport System
gCTS allows for the management of ABAP change and transport processes using Git as an external version control system. This feature is available from SAP S/4HANA 1909 onward.
With gCTS, developers can create and manage transport requests as Git branches and use standard Git commands to manage changes, such as committing, merging, and reverting changes. gCTS also supports branching and merging, which enables developers to work on multiple changes simultaneously and merge them into a single transport request.
I hope this helps! Below is a NEW book on SAP DevOPs…. Cheers!