 Anthony Cecchini is the President and CTO of Information Technology Partners (ITP), an ERP technology consulting company headquartered now in Virginia, with offices in Herndon. ITP offers comprehensive planning, resource allocation, implementation, upgrade, and training assistance to companies. Anthony has over 20 years of experience in SAP business process analysis and SAP systems integration. ITP is a Silver Partner with SAP, as well as an Appian, Pegasystems, and UIPath Low-code and RPA Value Added Service Partner. You can reach him at [email protected].
Anthony Cecchini is the President and CTO of Information Technology Partners (ITP), an ERP technology consulting company headquartered now in Virginia, with offices in Herndon. ITP offers comprehensive planning, resource allocation, implementation, upgrade, and training assistance to companies. Anthony has over 20 years of experience in SAP business process analysis and SAP systems integration. ITP is a Silver Partner with SAP, as well as an Appian, Pegasystems, and UIPath Low-code and RPA Value Added Service Partner. You can reach him at [email protected].
Organizations worldwide are depending on increasing data volumes to make strategic decisions. Data architecture is the solution for making sense of the large volume of data streaming into your business daily.
Data architecture entails how you translate your operation needs into system and data requirements. It also focuses on managing your data and its flow through your business. In a nutshell, it describes your business’s physical and logical data assets and your data management resources. The main objective of data architecture is to ensure that data flows seamlessly through your organization to fully leverage artificial intelligence while supporting your digital transformation. With a well-defined data architecture, you will get an environment that:
- Ensures optimal data quality.
- Allows you to integrate data from diverse sources.
- Guarantees a reliable system to secure your data.
- Serves as a single truth source about your organization.
- Enables stakeholders to make data-driven decisions and discover new insights.
DAMA-DMBOK 2(Data Management Association-Data Management Body of Knowledge 2), TOGAF (The Open Group Architecture Framework), FEAF (Federal Enterprise Architecture Framework), and Zachman Framework of Enterprise Architecture) are some popular data architecture frameworks. The article below will delve into data architecture to help you understand how best this fits into your venture and how to create it.
Components of Data Architecture 
Data architecture primarily comprises the following:
- Data pipeline: This is an end-to-end process entailing the collection, modification, storage, scrutiny, and delivery of data.
- Cloud storage offering a unique option for backing up data, securely storing it online, and easy sharing when permission is granted.
- API (application programming interface) to connect different computer programs or computers, essentially allowing them to ‘communicate.’
- Cloud computing for analysis and management of data. The process uses remote servers to support different services with the internet as its medium.
- Machine learning and artificial intelligence models that automate some tasks like data labeling and collection to cut back on costs and time. These models also hasten decision-making by negating human intervention.
- Data streaming that entails continuous data flow from a source to a destination for examination and processing in real or near real-time.
- Kubernetes: This is an open-source portable platform available as building blocks. It provides mechanisms for the maintenance, deployment, and scaling of data.
- Real-time analytics to analyze new data as soon as it arrives and derive insights that inform decisions.
Below is a diagram representing these components of data architecture.
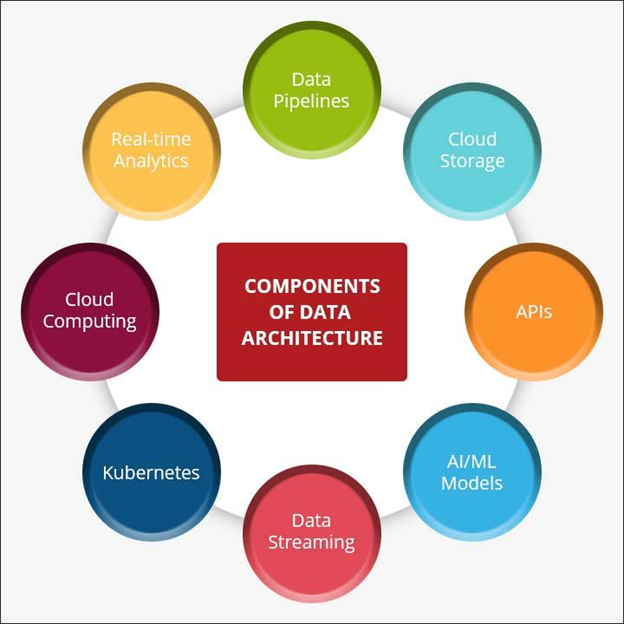
Principles of Data Architecture
Data architecture principles include rules pertaining to gathering, using, managing, and integrating data. These principles are the foundation of data architecture frameworks and help organizations form effective data strategies and make data-driven decisions. Below are these principles:
- Centralized data management. Successful data architectures view data as a shared asset. Remove departmental data silos so stakeholders have a 360-degree view of your company and correlate different data signals. This improves your corporate efficiency.
- Data curation. This entails producing, managing, and arranging data sets so users can effortlessly access the information they want. Curation enhances the overall experiences of data users and maximizes the value of your shared data.
- Consistent vocabulary. Shared data like fiscal calendar dimensions, KPIs, and product catalogs should use the same terminology to enable users to collaborate. Users of this shared data should also work from similar core definitions to maintain the control of data governance and data architecture.
- Restricted data movement and duplication. Each time you move data, this impacts its accuracy and increases its cost. Modern data architecture should ideally reduce data movement to boost data agility, improve data freshness and reduce expenses. The data is considered a shared asset and does not support departmental data silos, so everyone operates from one data version.
- System security. Your data architecture requires stringent access control and security policies for raw data. Nowadays, there are several technology solutions that facilitate self-service and built-in security features for data architectures without forfeiting access control.
- Custom user interfaces. Effective data architecture should provide interfaces that ease users’ access to data using the tools best suited to their tasks. The interface, in this case, is customized to a data’s purpose. For example, you can use an OLAP interface for BI, while data science best pairs with the R programming language.
Data Architecture Types
There are several data architecture types that can be used alone or together to make a robust whole to organize your data. The ideal type for your organization depends on your use and implementation, among other elements. Here are your data architecture options.
Data Lake
This data management framework stores, processes, and secure large amounts of semi-structured, unstructured, and structured data. If you have not yet to determine the purpose of your draw data, a data lake is the ideal architecture. Unfortunately, storing too much raw data carries the danger of your information getting unusable and too cluttered. You should thus adopt strong governance and data quality principles to guarantee data lakes favor your company.
Here is a diagram depicting the features of a data lake.
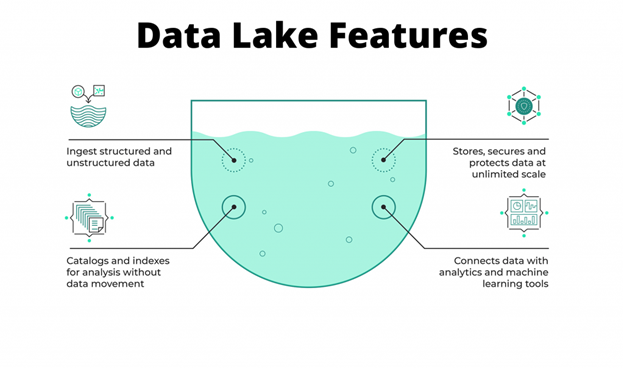
Data Warehouse
A data warehouse stores large amounts of business data and consolidates data from several systems, including sales, APIs, marketing, and customer-facing apps. ETL (extract, transform, load) tools like Panoply and Microsoft SQL Server Integration Services refine this data before moving it to the warehouse. You can then use the data collected to get insights that inform strategic decisions. Though data warehouses sound similar to data lakes, they store processed data, unlike the latter, which store unprocessed data. The information in a data warehouse has predefined purposes.
Below is a representation of a data warehouse.
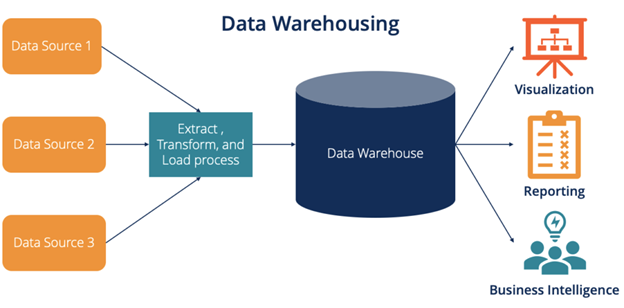
Data Vault
A data vault makes data architecture flexible, scalable, and agile by separating the structural information of your data (foreign relations and primary keys) from its attributes. In so doing, it supports the storage of historical information and parallel data loading so that you can scale without redesigning your entire architecture. Vaults solve the problem faced by organizations with several data sources that have to transform data into standard formats to create a unified source for data warehousing. Vaults store raw data without processing and then convert it on demand.
Data Fabric
The term ‘fabric’ can be interpreted as something that forms a structure to hold things together and becomes the basis of an item. Data fabric seamlessly connects different private, public, or hybrid clouds. In so doing, it unifies the data management across these distributed resources to control data security, mobility, access, and visibility while allowing data consistency. Unlike a data lake and warehouse, a data fabric does not have very defined and mature concepts and technologies. As such, you will find several vendor-specific implementations for it.
Data Mesh
Data mesh is among the newest ways of looking at information. It comes from a growing concept of viewing data in itself as a tool, product, and means to an end rather than something companies gather and then later analyze to understand what has already happened. Data mesh entails a data management approach using a distributed architectural framework. It spreads the responsibility and ownership of specific data sets across your business to those who can understand the data and harness its highest benefits.
The architecture used in data mesh compiles data from sources like data warehouses and data lakes. Essentially, it sorts and breaks down a large jumble of data into manageable chunks that are then distributed to decision-makers who can leverage it. Data lakes and data mesh both use big data, which is variable, unstructured, rapidly generated, and complex data.
Big data was stored in and accessed from the data lake initially. However, the latter lacked some analytic features, making it dependent on other platforms for transforming, indexing, analyzing, and querying data. Data lakes also had a complex ownership structure, failed to ensure data quality, and created bottlenecks that made data retrieval challenging. Data mesh arose to solve these issues and treat data as an essential tool for business management.
You might also confuse data mesh for data fabric. Data fabric aims to increase seamless approaches for managing unstructured information and complex metadata by merging advanced analytics, machine learning, and artificial intelligence. Conversely, data mesh depends on the technologies within the data fabric to integrate data management with human users depending on them.
Here is a representation of a data mesh implementation based on a real-time data product platform.
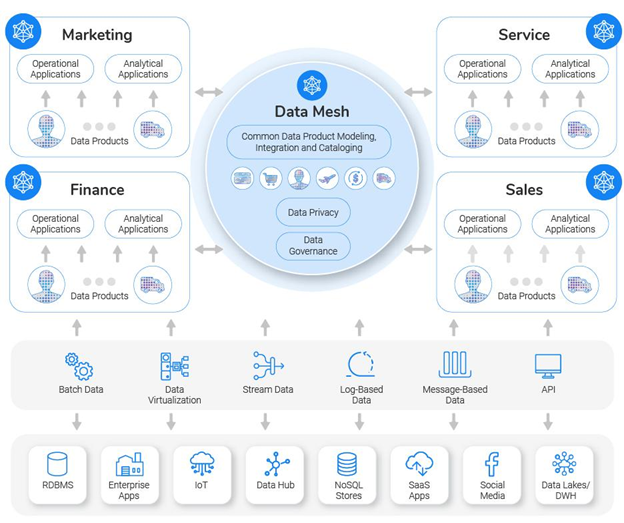
Best Practices for Building a Data Architecture
A well-organized data architecture will benefit your business by delivering an efficient data system that supports your decision-making and maximizes your profits while ensuring you remain competitive. To ensure you create the best data architecture, here are a few best practices to guide you.
- Break down your data silos so that information flows between datasets and remains in your central repository.
- Use ERDs (entity-relationship diagrams) to understand relationships between different data entities.
- Create a data architecture document to guide your development and have a compliance team regularly update the document.
- Ascertain that all the data in your architecture is trustworthy by cleansing and validating it.
- Consider different data formats and structures in your architecture. This is because unstructured and semi-structured data amounts have risen with the advent of cloud computing and big data.
- Keep an eye on the future and build data architecture that is flexible, agile, and scalable.
Summary
Data architecture seeks to manage the data flow through your enterprise by translating your company’s needs into system and data requirements. It achieves this using different approaches. These include data lake, data warehouse, data fabric, data mesh, and data vault. Though it is challenging to build a future-ready data architecture, focusing on the main principles and following the best practices will enable you to get a well-defined architecture to propel your business forward.

