Predictive Analytics adds efficiency to Trenitalia

TAKE NOTE (Insights into SAP solutions and Emerging Technology)
Italy’s primary train operator, Trenitalia, is combining the internet of things (IoT), analytics and in-memory computing in a project to make maintenance of its trains more efficient and effective.
Trains have complex mechanical and electrical systems with hundreds of thousands of moving parts. Trenitalia wants the project to enable it to predict failures before they happen, rather than just react to them.
To deliver a reliable service, trains need regular maintenance that can be triggered when a certain mileage is reached, after a particular time period, or by monitoring the condition of parts. Condition monitoring involves checking the operation of the equipment and only changing something if it shows signs of deterioration.
The IoT and the availability of complementary technologies have even made it possible to predict the failure of some items of equipment. This is what Trenitalia has started to do after deploying a dynamic maintenance management system (DMMS) that combines three technologies: the IoT, analytics and in-memory computing.
“SAP Hana is the platform that was selected to build the DMMS,” says Danilo Gismondi, CIO at Trenitalia. “It is now possible to affordably collect huge amounts of data from hundreds of sensors in a single train, analyze that data in real time and detect problems before they actually happen. This approach will be gradually introduced and will lower maintenance costs by up to 8%.
“The project was built according to the requirements expressed by the operation management and represents a paradigm shift. There is no more maintenance by mileage or by time. The goal is to keep costs to a minimum by applying predictive maintenance and data analytics to all essential railcar parts.”
Advances in sensor and communication technologies have enabled continuous data collection from various systems in trains. This means that mechanical and electrical conditions, operational efficiency and other performance indicators can be monitored 24 hours a day.
UNDER DEVELOPMENT(Information for ABAP Developers)
A Guide To Setting Up ALV User Managed Layouts
Introduction
In keeping in line with developing a feature-rich ALV grid for our users, in this final post we are going to add the LAYOUT functionality that will allow the changes made thus far by a user to be saved, and used again when the user logs on and runs our report. This is very much like how a variant is used for input; a Layout applies to how the output is formatted, sorted, filtered and displayed.
Adding User Managed Layouts to The ALV
Before we discuss how to add this functionality to our existing ALV code, lets look at what a user has the ability to do with our code at present. Below is a screen shot of the current SAP ALV Grid report, notice the RED highlighting around the cubed box. This is the “Change ALV Layout Button”.
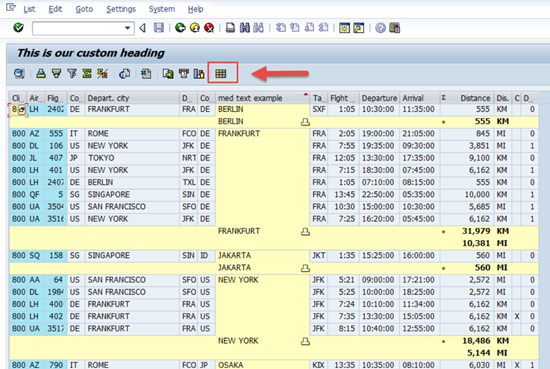
Lets go ahead and click this button. The below windowed dialog will open.
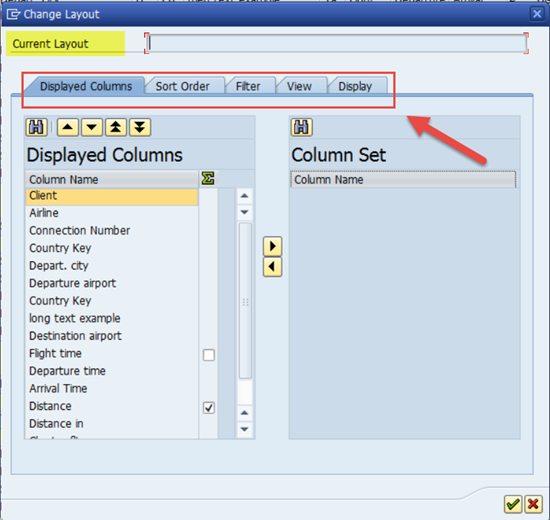
Notice that the Current Layout field is grayed out and cannot be edited. But, if we look across the tabs, we see we have a variety of ways to customize our UI experience with this ALV grid. In the DISPLAYED COLUMNS Tab, we can choose what columns to display. In the SORT ORDER Tab, we can choose what columns to sort on, whether ascending or descending, and whether to calculate sub-totals. In the FILTER Tab, we can choose to filter the results on certain fields and their contents. The VIEW Tab allows us to choose In-Line EXCEL or the SAP List Viewer. Finally in the DISPLAY Tab, we can choose to show grid-lines, optimize column width…etc.
So let’s go ahead and make some changes… I will remove the column MANDT. I will add an ascending sort by AIRLINE and remove Subtotals. Since I only care about American Airlines, I will create a filter for just that airline. Finally I will optimize the width. After I have clicked through the Tabs and applied all of these settings, I finally exit the dialog and now my ALV grid looks like this.

OK, this is exactly how I want to see the report the next time I execute it. But if I back out and try again, the report will default back to the original format. What happened to my layout? It would be nice to be able to quickly apply it again, without having to run through all the tabs. In fact, I may have a need for different layout versions, each a little different, that I want to choose from. How can I give a user functionality so they can not just change a layout, but save the changes as well? What about allowing a user to choose what layout they would like to superimpose onto the grid data?
Q&A (Post your questions to Facebook or Twitter and get the answers you need)
Q. Three of SAP’s biggest buzzwords right now are “in-memory computing,”
“big data,” and—of course—“SAP HANA.” Can you help clarify how these all relate?
A. The answer isn’t easy, and it involves more than just a description of a software solution….
Let’s start with In-memory computing…
The idea of running databases in memory is nothing new; it was one of the foundations of the business intelligence product QlikView, back in 1997. As this overall technology (in-memory) has matured, and memory prices have plummeted, it has become a viable and realistic option for organizations. This has opened the door for other software companies—for example, SAP—who have been working on ways to take advantage of this convergence of technology and affordability to build new and faster solutions for their customers.
At its core, in-memory computing is a technology that allows the processing of massive quantities of data in main memory to provide immediate results from analysis and transaction. SAP refers to this as massive parallel processing (MPP). The data to be processed is ideally real-time data or as close to real time as is technically possible. To achieve that level of performance, in-memory computing follows a simple tenet: speed up data access and minimize data movements. The main memory (RAM) is the fastest storage type that can hold a significant amount of data (while CPU registers and CPU caches are faster to access, their usage is limited to the actual processing of data). Data in main memory (RAM) can be accessed 100,000 times faster than data on a hard disk.
Now lets look at Big Data…
One of the reasons that in-memory computing is becoming such a big deal is because
of changing information consumption trends. The need for and requirements of data and visualization for organizations are rapidly changing, and are becoming more and more vital for the future. The importance of historical or trend reporting is decreasing, while data visualization and the ability to drive change continue to increase in importance.
The “big data” phrase is thrown around in the analytics industry to mean
many things. In essence, it refers to the massive—nearly inconceivable—amount of data that is available to us today. People create 2,500,000,000,000,000 bytes of
data per day. More than 90% of the world’s data has been created in the past two
years alone, and this pace isn’t slowing. This is FaceBook, Twitter, Blogs, Video, and is referred to as Unstructured Data. Structured Data is already stored in your database in the from of relational tables for transaction data. What does all this mean to you—the IT person who has to deal with all of this? If you are a business user, it means that you’ll want to incorporate all of this data into your repositories so you can bring it into your analysis. If you are an IT person, it means that you have to quickly look at strategies to deal with not only bringing in and storing massive amounts of data, but also making it available to your user community on an as-needed basis. Your paradigm has to shift, because the old way of capturing, staging, and storing data will no longer be sufficient. Both structured and unstructured data will continue to grow at astronomical rates, and you must address both of these types of data.
SAP HANA…
SAP HANA is a flexible, data source agnostic toolset (meaning it does not care where the data comes from) that allows you to hold and analyze large (massive) volumes of data in real time, without the need to aggregate or create highly complex physical data models. The SAP HANA in-memory database solution is a combination of hardware and software that optimizes row-based, column-based, and object-based database technologies to exploit parallel processing capabilities. The overall solution requires special hardware and includes software and applications, but at its heart, SAP HANA is a database.