 Anthony Cecchini is the President and CTO of Information Technology Partners (ITP), an ERP technology consulting company headquartered now in Virginia, with offices in Herndon. ITP offers comprehensive planning, resource allocation, implementation, upgrade, and training assistance to companies. Anthony has over 20 years of experience in SAP business process analysis and SAP systems integration. ITP is a Silver Partner with SAP, as well as an Appian, Pegasystems, and UIPath Low-code and RPA Value Added Service Partner. You can reach him at [email protected].
Anthony Cecchini is the President and CTO of Information Technology Partners (ITP), an ERP technology consulting company headquartered now in Virginia, with offices in Herndon. ITP offers comprehensive planning, resource allocation, implementation, upgrade, and training assistance to companies. Anthony has over 20 years of experience in SAP business process analysis and SAP systems integration. ITP is a Silver Partner with SAP, as well as an Appian, Pegasystems, and UIPath Low-code and RPA Value Added Service Partner. You can reach him at [email protected].
Data loss is a common phenomenon that software users often encounter at work. Although the largest data loss occurs from hardware malfunction, other factors such as software corruption, malware, and natural disasters also play a critical role. In a data loss, a good DBMS should ensure easy and faster data recovery.
The SAP HANA database is an excellent DBMS/appliance when it comes to data recovery. It stores data from the main memory to the secondary disk at frequent intervals during operation. Thus, if there is a power outage or database failure, your system continues running without interruption.
In this blog, we explore how SAP HANA Data recovery works and some essential features that enable easy retrieval after a data loss.
SAP HANA Data Availability After Recovery 
A backup process helps reinstate the data toward its former state if a fault occurs. Backups of data and log sets can be either modular or automated. SAP HANA also automatically synchronizes your storage space across multiple servers and services. The platform backs all systems that require data persistence while the system operates.
SAP HANA Data Recovery Infrastructure
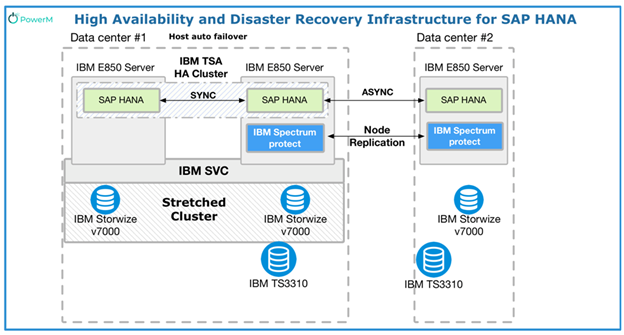
What Are Your Backup Options?
You’ll have several options for performing a backup of files and records, using the
SAP HANA module, namely:
- Backing up to a specific framework, for instance a Network File System (NFS).
- Endorsing a standby server using an SAP-certified agent’s execution of the programming interface.
- Backing up to external disk space as a memory snippet.
Can You Recover Files After Backup?
It is much easier to retrieve all files backed up in the SAP HANA platform.
However, during restoration, the processes will temporarily halt your data sets. Thus, you can use the SAP HANA cockpit to initiate and track the restoration process.
Here are some alternatives to consider for data retrieval…
#1 Using Recent Data Logs to Restore HANA
You can restore your data to the most recent state by incorporating a backup file or a storage snippet. Additionally, you can add a file backup systems post for that recovery spot and any records still accessible in the check area.
Predefined Data Periods
You can restore data backups using a backup file or a retrieval snippet at a predefined period. However, your retrieved data will have no log backups or log records after the predefined time.
#2 The Storage Replication System In SAP HANA
SAP HANA allows you to replicate ongoing persisted data, such as re-configuring dedicated transactions records. All replicated data translate to a virtual, integrated storage solution on a secondary SAP server.
The SAP HANA transaction at the primary data center will be complete when you recreate a transaction input at the primary data center in the secondary site.
This functionality, also known as ‘simultaneous memory reproduction,’ is only possible if both the secondary and primary locations are within 100 kilometers of each other.
The network administrator will connect a passive system to a storage device if you require a complete second domain. Furthermore, the administrator limits the possibility of having corrupted files from both frameworks copying data to the same disk space. Therefore, you must revive the SAP HANA framework to accomplish the data recovery process.
The storage replication system yields a smaller Recovery Point Objective. Thus, you can only lose minimal data, if any. Moreover, you will incur moderate expenses and a shorter waiting period before your system resumes normal operation.
However, the downside of storage multiplication is that when there is any problem to persistence for any reason, the malfunction replicates into subsequent processes.
#3 The Host Auto Failover In SAP HANA
An auto-back plan ensures supplementary system nodes back up a solitary or scale-out configuration. Although SAP HANA has several backup nodes, it only requires one extra node for the auto-failover plan. If one or more routine servers become defunct, the backup host immediately takes over.
If one of your servers fails, the backup host immediately obtains entry to the failed host’s data. As a result, you should allow your reserve server to access all data volumes available from shared network cloud storage.
When a fault occurs, the backup server connects to these backups via a distributed database or using merchant alternatives through the SAP storage adapters. All systems will automatically shift to the backup server when your host server crashes. Although this process occurs without the involvement of an outer subsystem manager, it does not occur in the event of a single product failure.
This Host-auto alternative has moderate added costs and an average recovery time objective. Because you must fill in data into the computer memory, the size of your dataset will be a key factor. It’s also a great choice for scale-out structures because it keeps your costs low and only requires a single additional server.
Auto Data Load In SAP HANA:
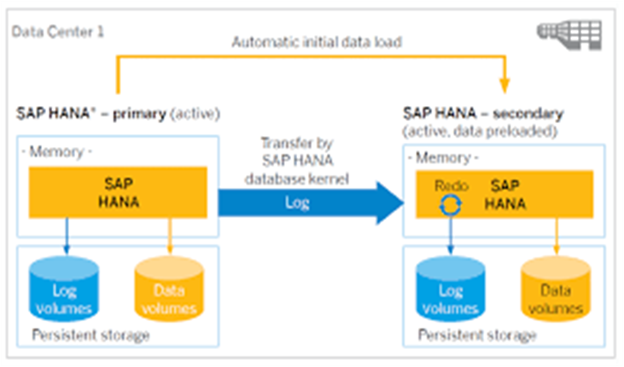 .
.
#4 System Replication of SAP HANA
The SAP HANA database has the ‘N + N’ propagation mode for framework and system replication. It contains an identical server with the same nodes as the backfield for every domain controller with N nodes. Be sure to place the two adjacent datasets in the configuration.
Alternatively, you can put the supplementary database in a remote location, although you require a strong connecting link between both servers.
This choice utilizes the live propagation mode. In this configuration, the supplementary SAP HANA system’s facilities will always contact those of the main unit. Moreover, the system will recreate all data and records of each transaction from the main process and store them in the supplementary system’s dataset using a common identification and entity number.
SAP HANA System Replication:
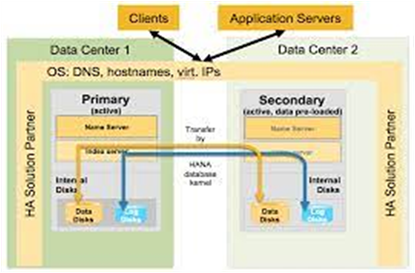
How Can You Configure the Backup?
There are several alternatives to configure the files in the main back up system. It all depends on whether the log transfer and files you copy to the disk space are discrete or continuous.
Below are some common modes of file configuration:
#1 Synchronous
The backup system sends a confirmatory message in synchronous mode when you encode the data. As a result, your file script is effective immediately after the data unit is active and published in instance log files.
Furthermore, when you disengage the secondary system, the primary process deactivates all process transactions until the link to the backup system is restored. As a result, you won’t lose any data.
#2 Synchronous In-memory
Unlike the synchronous mode, this file configuration format sends a response when the secondary system receives data. Therefore, you won’t have to wait until the system saves persisting data to perform a data configuration.
#3 Asynchronous
In the asynchronous mode, the main system does not require confirmation from the backup system. Therefore, you can set up your data even without an acknowledgment notification.
However, you should note that synchronous configurations highly depend on response time. As a result, high latency can significantly impact performance and should be used when you link both datasets with minimal networking.
For system propagation, there are two main modes:
Delta Data Shipping
The delta mode conveys data copies from the main unit to the backup system frequently. Thus, there won’t be a pile of used log information. Furthermore, the primary process communicates real-time updates about the column plates stored in your device memory.
Delta shipping transmits log data to the storage disk and submits deltas of all block modifications at frequent intervals, beginning from the last data log. It can also replay past logs to allow for restoration. The benefit of delta data shipping is its minimal minimum memory usage.
In the case of a fault in your system, the cloud manager activates live propagation mode for the backup server.
Log Replay
The log replay enables the storage server to re-create the log, reducing the required latency immediately.
In addition, you can customize the interconnection from the repository client and access the server using two possibilities.
They include:
- Using a private IP address to establish connection with the server and the file instance on that server.
- Using a Domain Names Service (DNS) to provide remote domain names. This alternative is costly but secures a cheaper recovery time and point objective.
All records conform to the secondary resources in the log replay configuration, resulting in less network activity between the frameworks. However, as memory usage grows, it becomes more difficult to use the peripheral device for non-production.
The read access feature allows SAP HANA system recompilation to facilitate non-edited entries on the backup system. This feature is based on the systematic log replay function and inherits its attributes. Because it allows for quick takeovers, it significantly reduces the need for frequency range.
An improved version is available in SAP HANA 2.0, with a faster loading rate. It can transfer data between the main and standby frameworks using multiple streams.
It also has quicker disk to data transfer time, enabling about 32 threads in sequential load. Moreover, the SAP 2.0 version gives you uninterrupted access to financial data while the primary process is restarting.
It can help accomplish read-intensive processes between a direct and indirect instance of SAP HANA. It also comes with a unified log storage device to make it possible for third-party instruments to back up data.
Summary
Data mishaps can be extremely inconvenient, but data retrieval from a save point is easier with SAP HANA.
The platform has an array of recovery features that you can implement on your database. From system replication, host auto failover, and storage replication, your data recovery is baked in.
Each of the alternatives has benefits and drawbacks.

