 Anthony Cecchini is the President of Information Technology Partners (ITP), an SAP consulting company headquartered in Pennsylvania. ITP offers comprehensive planning, resource allocation, implementation, upgrade, and training assistance to companies. Anthony has over 17 years of experience in SAP R/3 business process analysis and SAP systems integration. His areas of expertise include SAP NetWeaver integration; ALE development; RFC, BAPI, IDoc, Dialog, and Web Dynpro development; and customized Workflow development. You can reach him at [email protected].
Anthony Cecchini is the President of Information Technology Partners (ITP), an SAP consulting company headquartered in Pennsylvania. ITP offers comprehensive planning, resource allocation, implementation, upgrade, and training assistance to companies. Anthony has over 17 years of experience in SAP R/3 business process analysis and SAP systems integration. His areas of expertise include SAP NetWeaver integration; ALE development; RFC, BAPI, IDoc, Dialog, and Web Dynpro development; and customized Workflow development. You can reach him at [email protected].
Options for Determining Program Quality
You and I as ABAP developers understand that aside from design and code reviews, the most efficient technique for controlling program quality is during testing. By using the debugger, SQL Trace, and testing with real data, you can effectively monitor program performance, which of course, strongly depends on the dynamically executed code and the processed data.
I would like to continue the discussion from last month’s blog, focusing again on a preventive approach by using Static checks first to evaluate the quality of an object from its static definition. Good candidates for static checks include naming conventions, layout style guides, and other simple programming standards that are tightly associated with the static code. To some extent, you can also use static checks to look for the use of statements related to system stability and security.
Performance is NOT normally a problem on the development system, where adequate test data rarely exists, but it can quickly become one in the production system. Fortunately, you can make some assumptions about program performance based on static analysis. For example, by analyzing both the source code and the data dictionary definition, you can determine whether an Open SQL statement might become a performance bottleneck because of a badly coded WHERE clause, FOR ALL ENTRIES, or missing database index.
To perform static quality checks, you really need a tool for scanning a lot of source code and other object definitions efficiently. Starting back with SAP Web Application Server (Web AS) Release 6.10, we were given such a tool with the new SAP Code Inspector. It checks programs, function groups, classes, and other repository objects.
Whether you an experienced developer or a brand new one, my hope in this 3 part blog is to introduce you to the Code Inspector, so you can begin to utilize and leverage it’s power to help your ABAP development be the highest quality it can be.
This blog will loosely follow a 3 part format as outlined below:
– Present the Code Inspector SAP framework.
– Explain how to work with the SAP Code Inspector tool
– Introduce you to some important checks that are built-in and ready to use now.
The Code Inspector Framework
Let’s start by examining just how the Code Inspector supports the static analysis of ABAP programs and other development objects. By using this tool we can….
– Check single objects and object sets.
– Combine individual checks easily into a set (referred to as a check variant).
– Save and reuse object sets, as well as check variants (which can also be transported through the system landscape).
– Set parameters to control check behavior.
– Achieve fast check execution as a result of optional parallel processing.
– Access online documentation for checks and result messages.
– View all check results consistently in a hierarchical tree format.
– Navigate directly to the object that raises a message.
We can essentially break the Code Inspector framework into two functional areas:
The driver: The test driver defines and stores the test tasks (referred to as inspections), executes them, and stores and displays the results.
An extensible set of checks: The Code Inspector comes with many built-in checks (and more will be added in future releases), but as in any extensible framework, you can also define your own custom checks.
Lets look at the diagram below, then discuss it more detail….
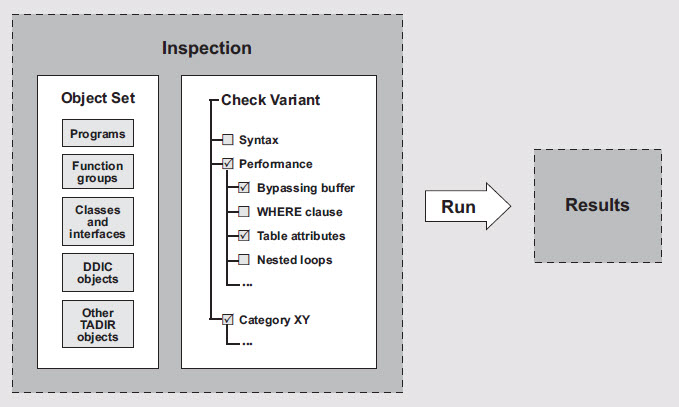
To use the Code Inspector, you work with elements that define and control its operation. So as outlined above, there is an inspection (the test you run) which consists of the combination of an object set (the objects you decide to scan) and a check variant (the set of checks you want to perform). Executing an inspection then produces the results as output.
Let’s examine each element in turn, in a little more detail…. We will work backwards and start with the CHECK VARIANT.
Check Variant
The Code Inspector comes with a host of individual checks that are organized into categories such as syntax, performance, and security. Some checks also have parameters that allow you to further control the scope of the check and its behavior. Therefore, the complete specification of a check is the individual check, extended by its parameters.
A check variant is a compilation of one or more individual checks. In order to apply a check to an object, you must first add the check to a check variant. You can name and save check variants for reuse, as well as transport them through the system landscape.
OK, now that we have a check variant that will perform all the kinds of checks we want, we need to specify what set of objects in the repository we want to check. Thus we define an OBJECT SET.
Object Set
Checks operate on objects. An object can be any development object that exists in an SAP system and has an entry in the catalog of repository objects (table TADIR). In other words, you can choose programs (reports, function groups, classes, interfaces), screens, user interfaces, database definitions, global types, and so on. An object set is the specification of the list of objects you want to scan. You can also save and reuse object sets, which are identified by a name and a version number.
OK, we have a list or set of objects we want to scan. We have a set of checks we want to perform against our list of objects. Now we can execute an INSPECTION.
Inspection
An inspection is the specification of the test, as stated above, consists of two components:
– The checks to be performed, according to the specified check variant
– The object set on which to execute the checks
An inspection can be either anonymous or named. Anonymous inspections are temporary and not persisted; named inspections are saved with a name and a version number. A named inspection can be run serially, or in parallel by several tasks for faster execution. After completion of an inspection, a named inspection contains an additional component — the results. Named inspections are designed to handle large object sets (usually, more than 10 objects) and are necessary if you need the results to be persisted. Maybe you need to attach the results along with a code review by your peers to satisfy a quality requirement where you work.
A good general rule of thumb is to use anonymous inspections for performing small, ad-hoc queries on single objects or small object sets, and when persistence is not required.
You now have a good foundation on the components of a Code Inspector inspection. In the next blog we will dive in on how to create these components and use them in an inspection, and examine the results.

